Server Monitoring
Métriques CPU/charge/disque/Apache/Nginx avec alertes par seuil, suivi des connexions SSH et instantanés post-mortem.
Version 1.1.7 · Extension Store · requiert PHP 7.4+ avec
sqlite3+pdo_sqliteSuivi en direct des connexions SSH avec notifications par courriel, et 30 jours d'historique CPU / charge / disque / workers Apache avec alertes par seuil.
Server Monitoring est une pile de surveillance légère, pilotée par cron (sans démon), avec trois piliers :
- Métriques — échantillons à la minute du CPU / attente E/S, charge moyenne, usage disque par point de montage, workers Apache et connexions Nginx, stockés en SQLite avec alertes par seuil + durée + temps de repos.
- Connexions SSH — chaque authentification SSH réussie de
/var/log/secureest enregistrée et (optionnellement) envoyée par courriel, avec classification de risque par IP source. - Instantanés — une large coupe de l'état du système (processus, scoreboard Apache, processlist MySQL, dmesg, …) capturée manuellement ou automatiquement quand une alerte se déclenche — une aide post-mortem même si le serveur tombe ensuite.
C'est aussi la seule extension réellement utile sur les nœuds cPanel DNSOnly.
Onglet Metrics
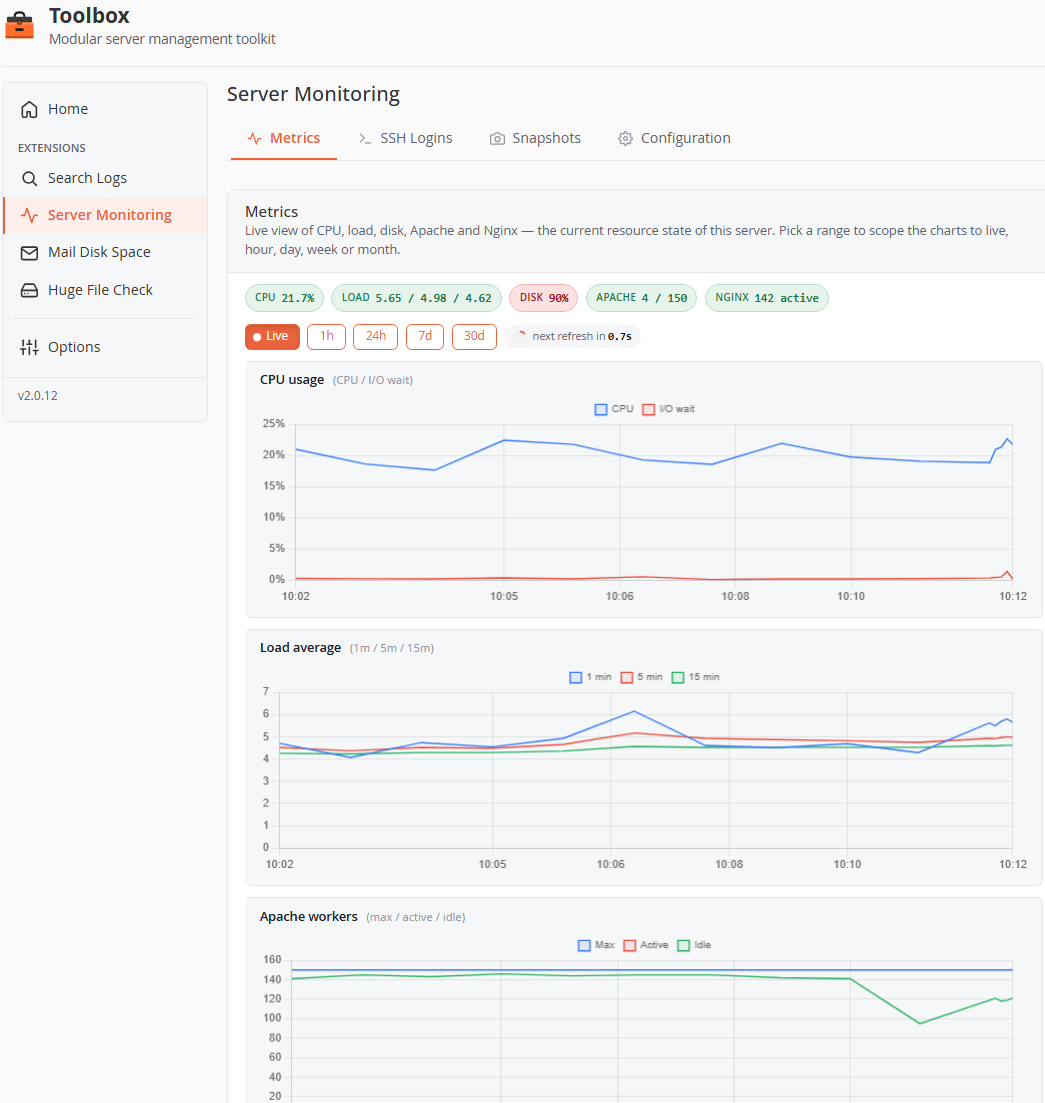
- Status chips — valeurs courantes d'un coup d'œil (CPU, Load, Disk, Apache, Nginx), teintées selon leur proximité avec les seuils d'alerte.
- Sélecteur de plage —
Live(10 dernières min, rafraîchi toutes les 5 s avec compte à rebours),1h,24h,7d,30d. - Graphiques (lignes pleine résolution, un bloc par groupe de métriques) :
- CPU usage — CPU % et attente E/S %.
- Load average — 1 / 5 / 15 minutes.
- Apache workers — max / actifs / inactifs, plus un graphique distinct des états de requête (reading, sending, keepalive, …).
- Nginx connections — active / reading / writing / waiting.
- Disk usage — une ligne par point de montage, axes fixés 0–100 %.
- Les seuils d'alerte sont tracés directement sur les graphiques. Désactiver un groupe de métriques dans la Configuration masque son graphique et arrête sa collecte.
Onglet SSH Logins
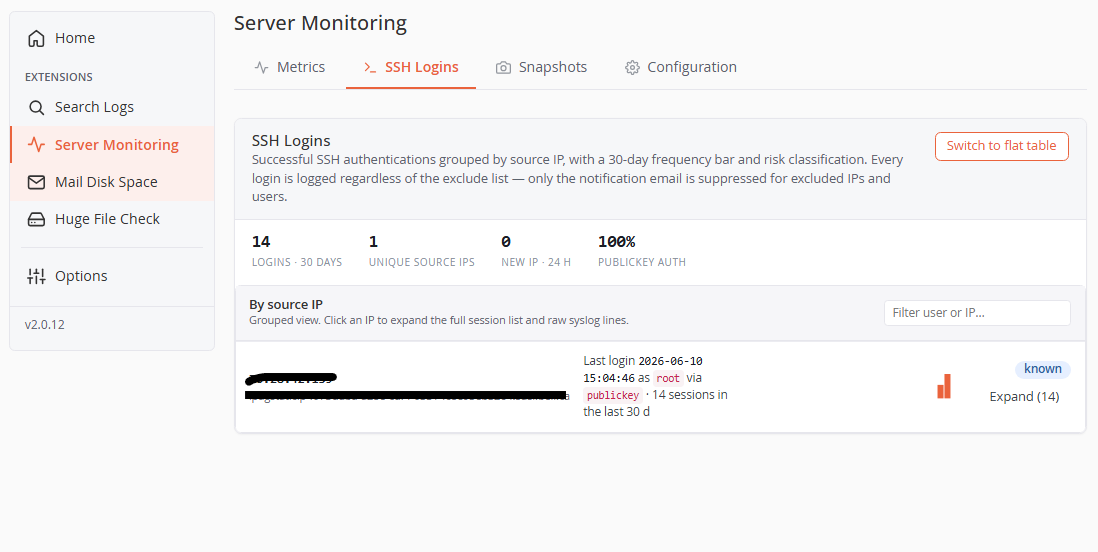
Authentifications SSH réussies regroupées par IP source (vue par défaut), avec :
- Ligne de stats — total des connexions (30 j), IP sources uniques, nouvelles IP (24 h), pourcentage d'auth par clé publique.
- Lignes par IP — IP + nom DNS inversé (résolu de façon asynchrone), dernière connexion (utilisateur, méthode), une barre de fréquence sur 30 jours, et un badge de risque :
- New IP (rouge) — vue pour la première fois il y a moins de 24 h. Les nouvelles IP sont aussi mises en avant dans une bannière en haut, avec un raccourci vers la liste d'exclusion.
- Trusted (vert) — vue sur 5+ jours distincts.
- Known (bleu) — tout le reste.
- Excluded (gris) — dans la liste d'exclusion (ligne atténuée).
- Expand (N) — charge à la demande la liste complète des sessions avec les lignes syslog brutes de cette IP.
- Switch to flat table — un tableau classique filtrable/paginé (When / User / Source IP / Method / Raw syslog) si vous préférez.
Chaque connexion est enregistrée quelles que soient les listes d'exclusion — l'exclusion ne supprime que le courriel de notification, jamais la piste d'audit.
Onglet Snapshots
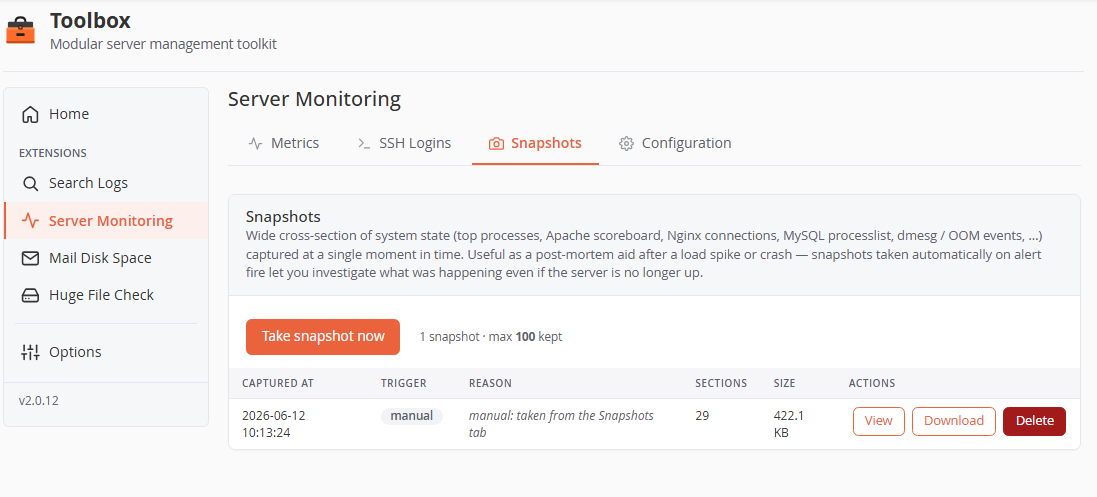
- Take snapshot now — capture à la demande. Les instantanés automatiques se déclenchent quand une alerte survient (configurable, avec un temps de repos pour que les incidents multi-métriques n'empilent pas les captures).
- Chaque instantané indique l'heure de capture, le déclencheur (
manual/auto), la raison (ex.alert: cpu_pct exceeded 90%), le nombre de sections et la taille, avec View (fenêtre en navigateur), Download (ZIP) et Delete.
Un instantané capture ~29 sections réparties en 8 groupes, chaque commande isolée avec un délai de 60 secondes (une section qui échoue ne gâche jamais le reste) :
| Groupe | Contenu |
|---|---|
| system | uptime, free -m, df -h, df -i (inodes !), vmstat 1 3, fin de dmesg |
| processes | top par CPU, top par mémoire, arbre complet des processus |
| network | résumé des sockets (ss -s), connexions établies avec PID, top des IP sources HTTP |
| apache | HTML complet de mod_status (détail par worker) |
| nginx | stub_status + détail par connexion |
| mysql | processlist, compteurs de statut, statut InnoDB, fin du journal des requêtes lentes |
| logs | messages, maillog, événements OOM de dmesg, journaux d'erreur Apache/Nginx |
| cpanel | statut des services (whmapi1), longueur de la file Exim, erreurs journalctl, journal d'erreur cPanel |
La rétention est par compte (défaut 100 instantanés ; les plus anciens élagués).
Onglet Configuration
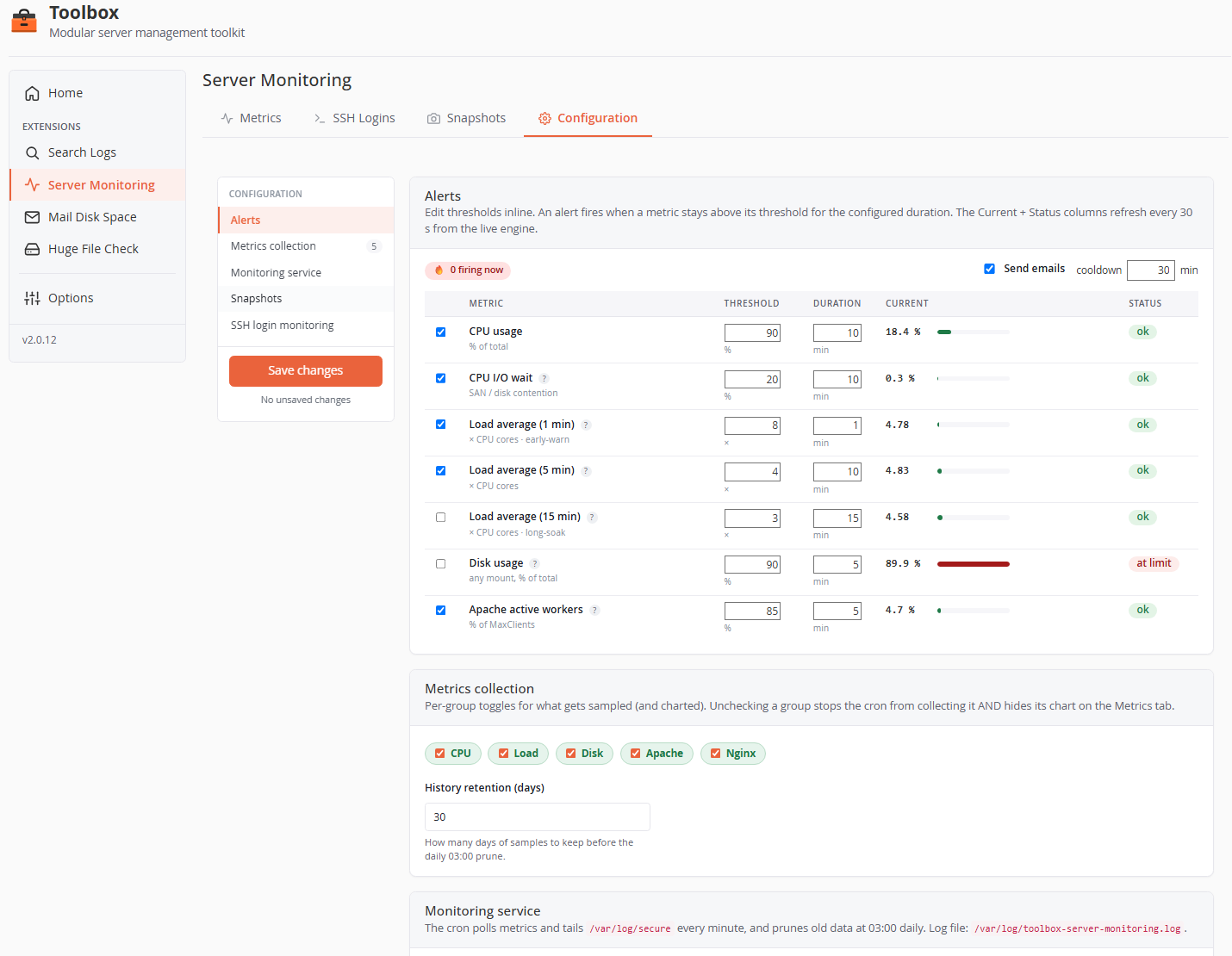
Disposition en deux colonnes : navigation par section avec un bouton Save changes collant (et un compteur de changements non enregistrés) à gauche, réglages à droite.
Alertes
Une alerte se déclenche quand une métrique reste au-dessus de son seuil pendant toute la fenêtre de durée (chaque échantillon consécutif), et se rétablit quand elle redescend — avec un courriel de rétablissement si le déclenchement a été notifié. Les colonnes Current et Status se rafraîchissent en direct toutes les 30 s.
| Métrique | Seuil par défaut | Durée par défaut | Activée par défaut |
|---|---|---|---|
| Usage CPU (% du total) | 90 % | 10 min | oui |
| Attente E/S CPU (%) | 20 % | 10 min | oui |
| Charge moyenne 1 min (× cœurs CPU) | 8× | 1 min | oui (alerte précoce) |
| Charge moyenne 5 min (× cœurs CPU) | 4× | 10 min | oui |
| Charge moyenne 15 min (× cœurs CPU) | 3× | 15 min | non (signal de longue durée) |
| Usage disque (% par montage) | 90 % | 5 min | non (cPanel surveille déjà le disque) |
| Workers Apache actifs (% de MaxClients) | 85 % | 5 min | oui |
- Send emails — interrupteur maître des notifications d'alerte (l'état reste suivi quand désactivé, donc la réactivation est transparente).
- Cooldown (défaut 30 min) — intervalle minimal entre deux notifications pour la même métrique.
- Les seuils de charge sont par cœur — multipliés par le nombre de CPU à l'évaluation, donc une seule config fonctionne sur des serveurs hétérogènes.
Collecte des métriques
- Bascules de groupe — pastilles CPU / Load / Disk / Apache / Nginx. Décocher un groupe arrête sa collecte et masque son graphique.
- History retention (days) — défaut 30 ; appliqué par l'élagage quotidien de 03:00.
Service de surveillance
Montre si le cron est installé, le dernier tick, et un bouton Enable cron / Disable. Le cron (/etc/cron.d/toolbox-server-monitoring) exécute :
poll-metrics.php— chaque minute : collecte les échantillons (~80–200 ms), évalue les alertes, expédie les notifications et les instantanés automatiques.tail-ssh.php— chaque minute : lit/var/log/securedepuis un curseur enregistré (conscient des rotations), enregistre les connexions, envoie les notifications.prune-history.php— chaque jour à 03:00 : applique la rétention ; compacte SQLite le 1er du mois.
Les trois écrivent une ligne par exécution dans /var/log/toolbox-server-monitoring.log.
Instantanés
| Réglage | Défaut |
|---|---|
| Activer les instantanés (maître — off désactive auto et manuel) | on |
| Capture auto sur alerte (les alertes d'usage disque sont sautées — un disque plein n'a pas besoin d'un instantané qui le remplit davantage) | on |
| Lien dans le courriel d'alerte (lien direct vers l'instantané) | on |
| Max d'instantanés conservés | 100 |
| Écart min entre captures auto (min) | 5 |
Surveillance des connexions SSH
| Réglage | Défaut | Notes |
|---|---|---|
| Courriel à chaque connexion | on | Les connexions sont quand même enregistrées quand off. |
| Sudoers seulement | on | Seuls les membres root/wheel sont suivis ; les utilisateurs cPanel sont entièrement filtrés. |
| Exclure des utilisateurs | vide | Séparés par virgule/espace. Les utilisateurs exclus apparaissent quand même dans l'historique — seul le courriel est supprimé. |
| Exclure des IP | vide | IPv4 + IPv6, correspondance exacte (pas de CIDR). |
| Temps de repos de notification (min/utilisateur) | 10 | Un utilisateur qui se reconnecte dans la fenêtre ne déclenche pas un second courriel. |
| Rétention d'historique (jours) | 45 |
Notifications envoyées
Toutes via le Notifier du noyau (voir Configuration du noyau → Notifications), priorité high :
SSH login: <user>@<hostname>— hôte, utilisateur, IP source, méthode d'auth, heure, avec une invite « enquêter immédiatement ».<Metric> exceeded on <hostname>— métrique, valeur courante, seuil, durée ; inclut un lien vers l'instantané auto-capturé le cas échéant.Recovered: <Metric> on <hostname>— envoyé quand une alerte notifiée se résorbe.
Carte des données et fichiers
| Chemin | Rôle |
|---|---|
extensions/server-monitoring/var/monitoring.db |
SQLite : metrics (30 j), ssh_logins (45 j), rdns_cache |
extensions/server-monitoring/var/snapshots/ |
ZIP d'instantanés (max 100) |
extensions/server-monitoring/var/*.json |
État des alertes, curseur SSH, temps de repos de notification, caches d'échantillons CPU |
extensions/server-monitoring/config/settings.default.json + var/settings.user.json |
Défauts + vos surcharges |
/etc/cron.d/toolbox-server-monitoring |
Les trois tâches cron |
/var/log/toolbox-server-monitoring.log |
Une ligne par exécution cron (facile à grep) |